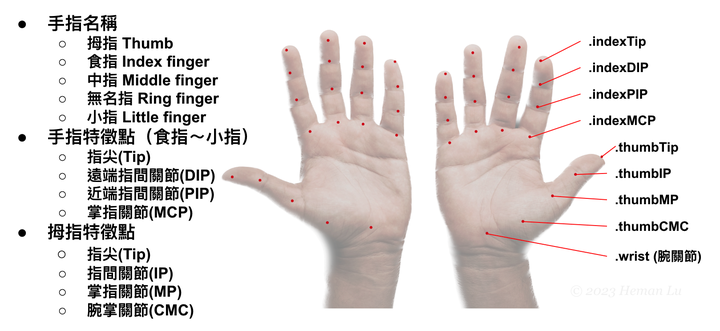
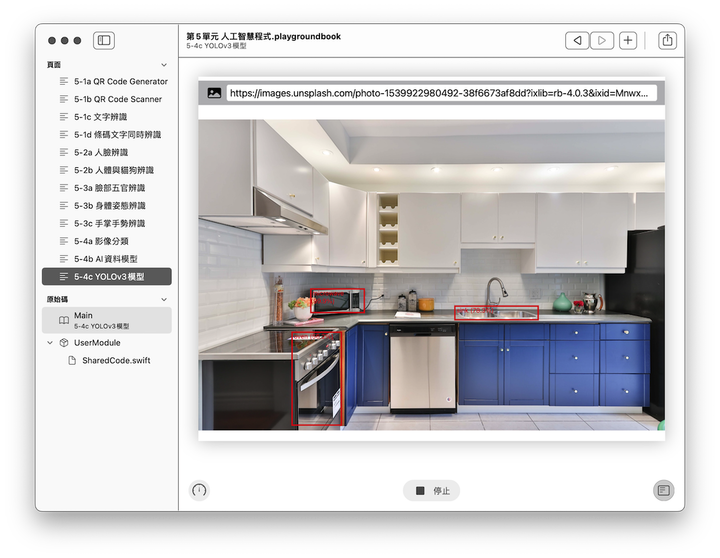
上一節我們學會辨識臉部細節,取得76個特徵點,據此可做出身分識別或臉部表情相關應用。本節我們將學習辨識全身肢體動作,需要多少特徵點呢?其實只要19個特徵點,就能判別一個人舉手投足或站坐蹲臥等姿態,甚至進一步分析運動員或健身教練的動作。
全身19個特徵點如下圖所示,我們身體是左右對稱,左右兩側分別有眼、耳、肩、肘、腕、臀、膝、踝等8個部位,身體中線只取鼻、頸、臍等3個位置,合計19個特徵點,如下圖。
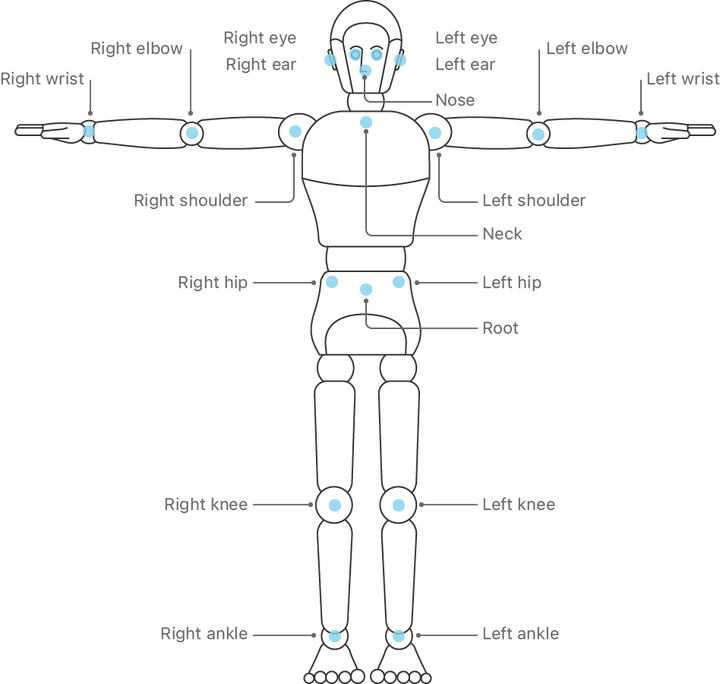
圖片來源:Apple原廠文件
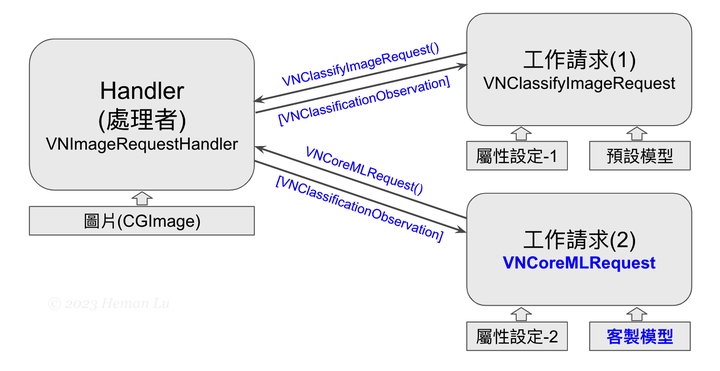
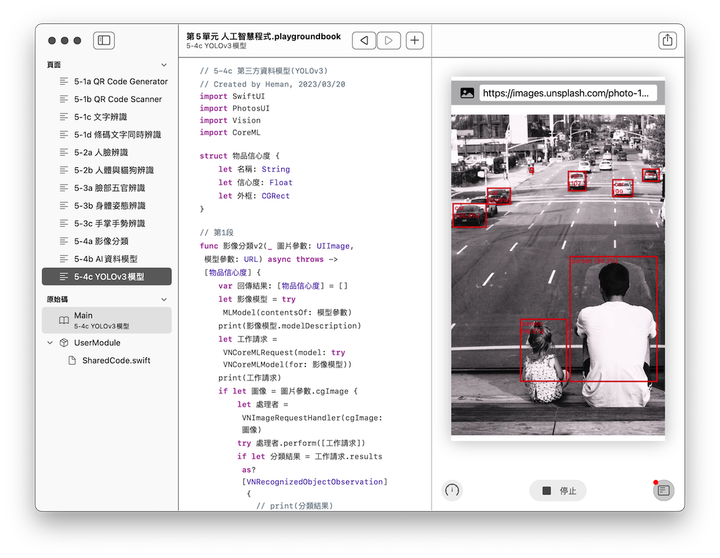
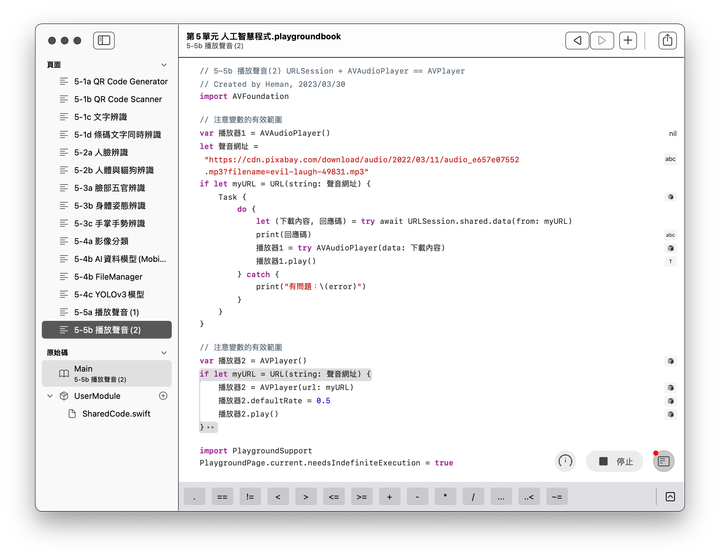
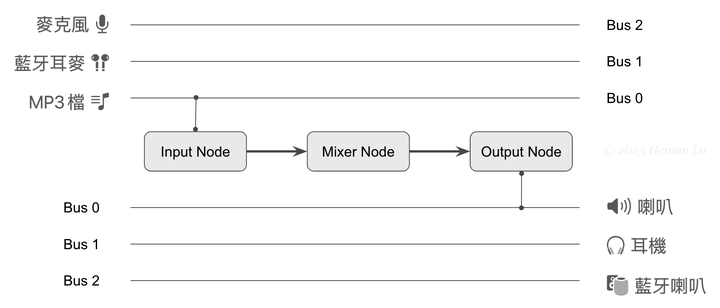
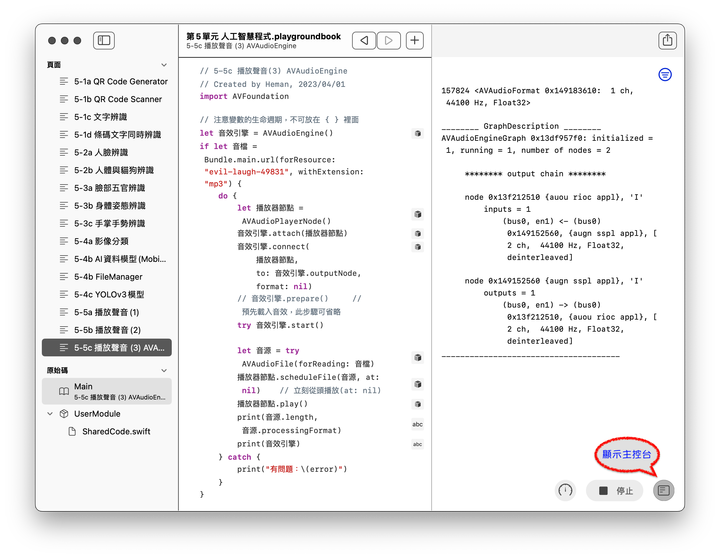
辨識身體姿態的第1段程式如同前一節,將工作請求換成 VNDetectHumanBodyPoseRequest,關鍵字Pose 是姿勢、姿態的意思。程式碼如下,函式將回傳特徵點的正規化座標 [CGPoint]:
import Vision
// 第1段
func 身體姿態辨識(_ 圖片參數: UIImage) async throws -> [CGPoint] {
var 結果: [CGPoint] = []
let 工作請求 = VNDetectHumanBodyPoseRequest()
if let 影像 = 圖片參數.cgImage {
let 處理者 = VNImageRequestHandler(cgImage: 影像)
try 處理者.perform([工作請求])
if let 處理結果 = 工作請求.results { // as? [VNHumanBodyPoseObservation]
print("處理結果:\(處理結果)")
for 軀體 in 處理結果 {
let 所有特徵點 = try 軀體.recognizedPoints(.all)
let 全身關節: [VNHumanBodyPoseObservation.JointName] = [
.leftEye, .leftEar, .leftShoulder, .leftElbow,
.leftWrist, .leftHip, .leftKnee, .leftAnkle,
.nose, .neck, .root,
.rightEye, .rightEar, .rightShoulder, .rightElbow,
.rightWrist, .rightHip, .rightKnee, .rightAnkle
]
for i in 全身關節 {
if let 特徵點 = 所有特徵點[i] {
if 特徵點.confidence > 0 {
結果.append(特徵點.location) // 正規化座標
}
}
}
}
}
}
if 結果.isEmpty { 結果.append(CGPoint.zero) }
print("回傳結果:\(結果)")
return 結果
}
注意這裡如何取得所有特徵點的座標,與上一節稍有不同,當我們執行:
let 所有特徵點 = try 軀體.recognizedPoints(.all)
並不是直接取得所有特徵點的座標陣列,而是一個特殊的資料結構,稱為字典(dictionary),字典和陣列類似,差別在於字典可用任何資料類型當索引,若不了解沒關係,可參考下一節語法說明。
在此段函式中,辨識結果的字典是以19個特徵點的名稱當索引,例如,用「所有辨識點[.leftEye]」可取得左眼特徵點的資料(裡面包含 confidence 信心度與 location 點座標)。
因此,我們將19個特徵點名稱全部列出來,然後逐一當做索引,即可取得身體所有特徵點資料,如果該點信心度 confidence > 0,表示資料有效,就將其正規化座標 location 加入結果陣列中回傳,這段程式碼如下:
let 全身關節: [VNHumanBodyPoseObservation.JointName] = [
.leftEye, .leftEar, .leftShoulder, .leftElbow,
.leftWrist, .leftHip, .leftKnee, .leftAnkle,
.nose, .neck, .root,
.rightEye, .rightEar, .rightShoulder, .rightElbow,
.rightWrist, .rightHip, .rightKnee, .rightAnkle
]
for i in 全身關節 {
if let 特徵點 = 所有特徵點[i] {
if 特徵點.confidence > 0 {
結果.append(特徵點.location) // 正規化座標
}
}
}
實際執行發現,有些特徵點被擋住或在畫面之外,信心度就會下降,若完全看不到也無法推測,信心度就變成0,這些點就不必回傳。
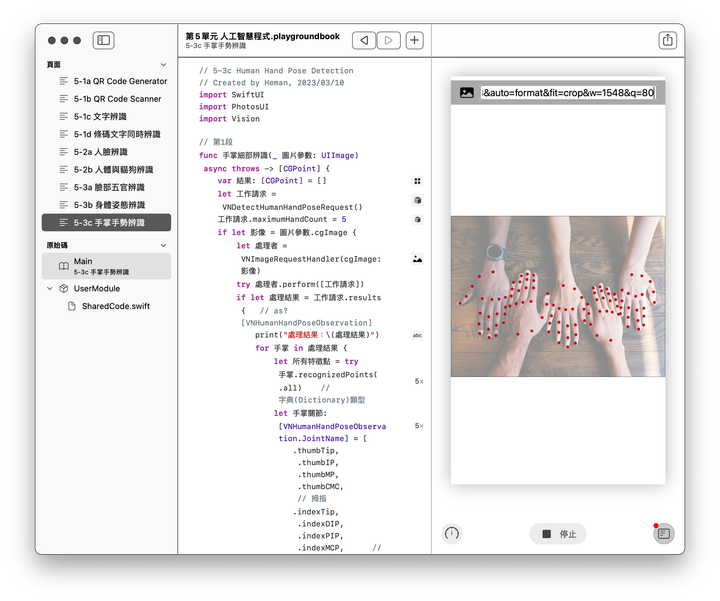
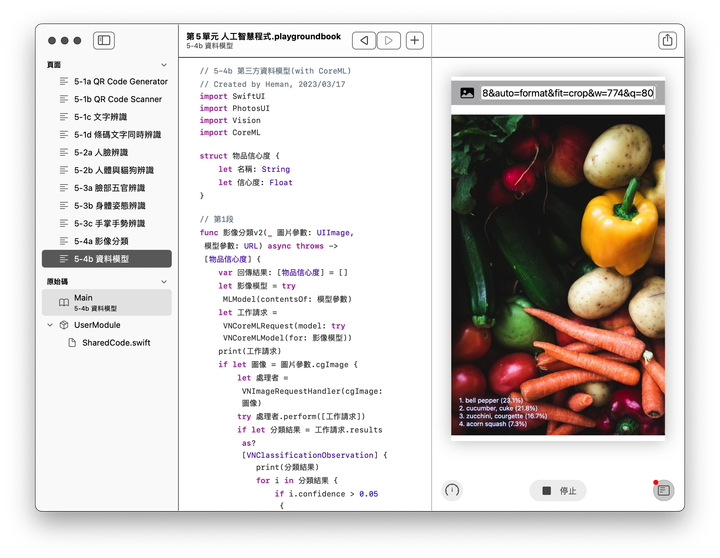
寫好第1段之後,基本就算完工了,後面4段均可沿用上一節,執行結果如下圖(圖片來源網址請參考附註),相當有趣:
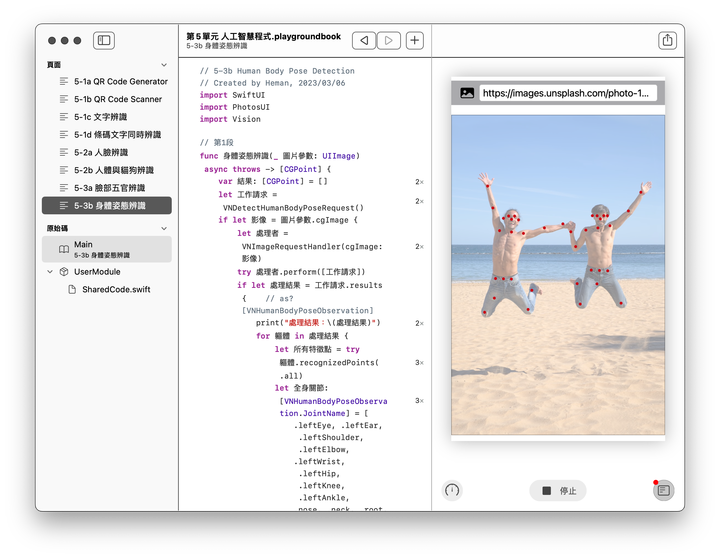
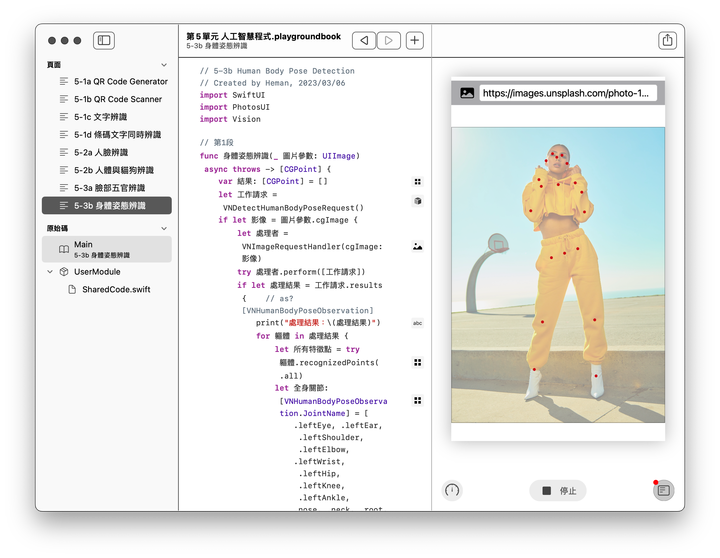
完整程式碼如下:
// 5-3b Human Body Pose Detection
// Created by Heman, 2023/03/06
import SwiftUI
import PhotosUI
import Vision
// 第1段
func 身體姿態辨識(_ 圖片參數: UIImage) async throws -> [CGPoint] {
var 結果: [CGPoint] = []
let 工作請求 = VNDetectHumanBodyPoseRequest()
if let 影像 = 圖片參數.cgImage {
let 處理者 = VNImageRequestHandler(cgImage: 影像)
try 處理者.perform([工作請求])
if let 處理結果 = 工作請求.results { // as? [VNHumanBodyPoseObservation]
print("處理結果:\(處理結果)")
for 軀體 in 處理結果 {
let 所有特徵點 = try 軀體.recognizedPoints(.all)
let 全身關節: [VNHumanBodyPoseObservation.JointName] = [
.leftEye, .leftEar, .leftShoulder, .leftElbow,
.leftWrist, .leftHip, .leftKnee, .leftAnkle,
.nose, .neck, .root,
.rightEye, .rightEar, .rightShoulder, .rightElbow,
.rightWrist, .rightHip, .rightKnee, .rightAnkle
]
for i in 全身關節 {
if let 特徵點 = 所有特徵點[i] {
if 特徵點.confidence > 0 {
結果.append(特徵點.location) // 正規化座標
} else {
print(i, 特徵點.confidence, 特徵點.location)
}
}
}
}
}
}
if 結果.isEmpty { 結果.append(CGPoint.zero) }
print("回傳結果:\(結果)")
return 結果
}
// 第2段
// Updated by Heman, 2024/12/24. 重新改寫
struct 相簿單選: View {
@State var 單選: PhotosPickerItem?
@Binding var 圖片: UIImage?
var body: some View {
if 圖片 == nil {
PhotosPicker(selection: $單選) {
VStack {
Image(systemName: "barcode.viewfinder")
.resizable()
.scaledToFit()
Text("請點選條碼照片")
.font(.title)
}
}
.photosPickerStyle(.inline)
.photosPickerAccessoryVisibility(.hidden, edges: .leading)
.onChange(of: 單選) { 選擇結果 in
Task {
do {
if let 原始資料 = try await 選擇結果?.loadTransferable(type: Data.self) {
if let 轉換圖片 = UIImage(data: 原始資料) {
圖片 = 轉換圖片
}
}
} catch {
print("無法取得或轉換照片: \(error)")
圖片 = nil
}
}
}
} else {
Image(uiImage: 圖片!)
.resizable()
.scaledToFit()
}
}
}
// 第3段
struct 照片掃描: View {
@State var 點座標陣列: [CGPoint] = []
@State var 相簿圖片: UIImage? = nil
var body: some View {
網址抓圖(圖片: $相簿圖片) // 第5段
.onChange(of: 相簿圖片) { 新圖片 in
點座標陣列 = []
Task {
do {
點座標陣列 = try await 身體姿態辨識(新圖片 ?? UIImage()) // 第1段
} catch {
print("無法辨識圖片:\(error)")
}
}
}
Spacer()
if 相簿圖片 == nil {
相簿單選(圖片: $相簿圖片) // 第2段
} else {
ZStack() {
Image(uiImage: 相簿圖片!)
.resizable()
.scaledToFit()
.border(Color.secondary)
.opacity(0.5) // 將圖片淡化作為底圖
.overlay(描繪特徵點(正規化點陣列: 點座標陣列)) // 第4段
.onTapGesture {
相簿圖片 = nil
點座標陣列 = []
}
if 點座標陣列.isEmpty {
ProgressView()
.scaleEffect(2.5)
}
}
}
Spacer()
}
}
// 第4段
struct 描繪特徵點: View {
let 正規化點陣列: [CGPoint]
var body: some View {
Canvas { 圖層, 尺寸 in
// print(尺寸)
let 圖寬 = 尺寸.width
let 圖高 = 尺寸.height
var 畫筆 = Path()
for 單點 in 正規化點陣列 {
let 點座標 = CGPoint(
x: 圖寬 * 單點.x,
y: 圖高 - 圖高 * 單點.y)
畫筆.move(to: 點座標)
畫筆.addArc(
center: 點座標,
radius: 3.0,
startAngle: .zero,
endAngle: .degrees(360),
clockwise: false)
}
圖層.fill(畫筆, with: .color(.red))
}
}
}
// 第5段
struct 網址抓圖: View {
@Binding var 圖片: UIImage?
@State var 網址: String = ""
var body: some View {
ZStack {
Rectangle()
.foregroundColor(.gray.opacity(0.5))
.frame(height: 50)
HStack {
Image(systemName: "photo.fill")
.font(.system(size: 24))
TextField("輸入圖片網址", text: $網址, prompt: Text("https://"))
.font(.system(size: 20))
.background(Color.white)
.textFieldStyle(.roundedBorder)
.cornerRadius(5.0)
.onChange(of: 網址) { 新網址 in
Task {
if let myURL = URL(string: 新網址) {
let (原始資料, _) = try await URLSession.shared.data(from: myURL)
if let 格式轉換 = UIImage(data: 原始資料) {
圖片 = 格式轉換
} else {
print("非圖片網址,請重新輸入。")
}
} else {
print("網址格式錯誤,請重新輸入。")
}
}
}
}
.padding()
}
}
}
import PlaygroundSupport
PlaygroundPage.current.setLiveView(照片掃描())
💡 註解
- 本節範例圖片網址:
- https://images.unsplash.com/photo-1561688862-18158b0df99f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=776&q=80
- https://images.unsplash.com/photo-1515886657613-9f3515b0c78f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=1080&q=80
- 此處回傳的特徵點,左右方向與人物左右一致,不像上一節與人物相反。
- 電影拍攝常用一種稱為「動作捕捉(Motion Capture)」技術,來達到辨認姿態動作的效果,讓動畫特效更逼真,演員常須穿上特製的「動作捕捉服」,或是在臉上塗上黑點(標示特徵點)。