
轉職為全職 AI 創作人。今天不聊情懷,想跟大家分享一套我為了應對 2026 年 YouTube 重複內容(Reused Content)審核機制,在本地端建立的自動化處理架構。
【硬體環境與技術棧】
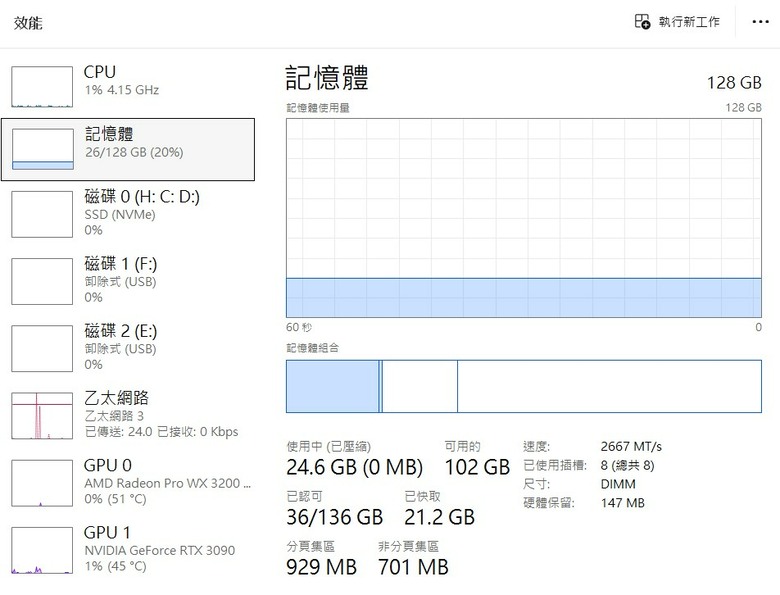
目前這套系統跑在我的二號工作站上,穩定性還不錯:
硬體:Lenovo R620 伺服器 (128GB RAM)
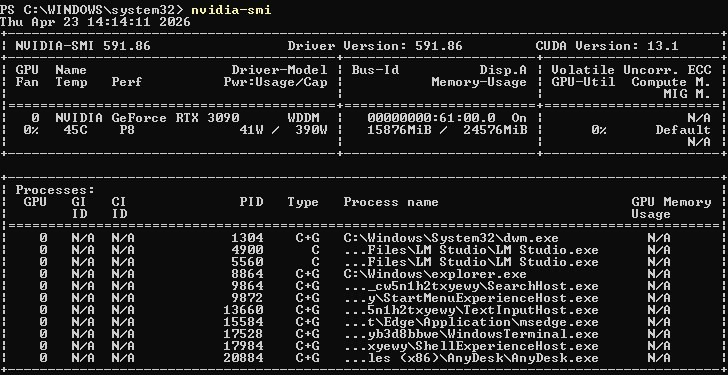
顯卡:ROG 3090 24GB VRAM + AMD 亮機卡
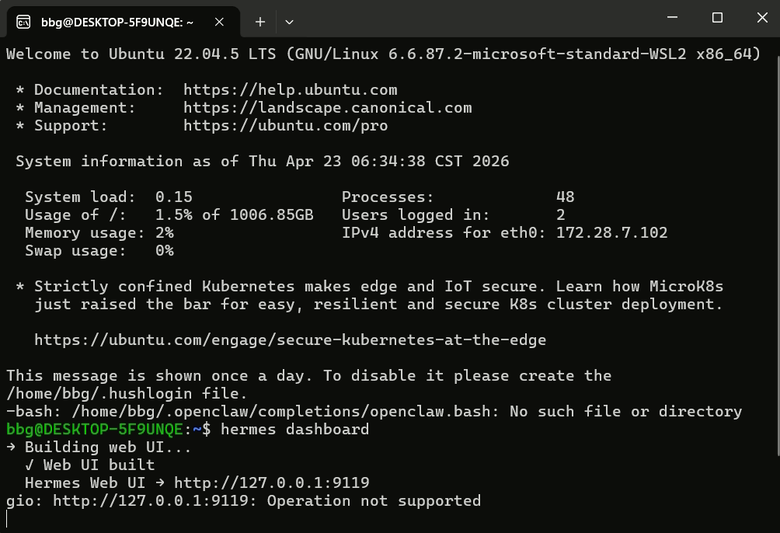
架構:Windows 11 + WSL2 (Ubuntu)
本地 AI 記憶:AnythingLLM(負責儲存開發 SOP 與特徵碼比對紀錄)
【核心邏輯:從「濾鏡」進化到「重構」】
影音平台的 AI 審核越來越嚴。我的思路是從兩個維度徹底改變文件的「數位指紋」:
音訊特徵碼重混 (Audio Fingerprint Reconstruction):
透過串接 Suno AI API,為每支影片動態生成原創 BGM。這能確保音軌在波形層面上與原素材完全脫鉤。
影像像素層級微調 (Pixel-level Metadata Randomization):
利用 Python 調動 GPU 轉檔,並在過程中對特徵碼進行微擾動。在不損失視覺品質(保持高 SSIM/PSNR 數據)的前提下,確保輸出的文件在二進制層面上具備唯一性。
【自動化流程實作】
目前透過一個 Logic Agent 監控 Pipeline。從原始影片投放到 D 槽共享資料夾,WSL 腳本會自動感應、抓取、調用 AI 進行處理。目前整套「自動化授權與派發」的閉環流程已經跑通,實測穩定度符合預期。
【結語】
在 AI 時代,我們不只是在用軟體,而是在構建「軟體體系」。不知道版上的前輩們對於這種「影音去重」的算法,或是對於 R620 的資源分配有沒有更好的建議?歡迎交流。






























































































