前陣子看到兩則新聞:美國新創 Aaru 用 AI agent 模擬選舉預測,中國也有個叫 MiroFish 的團隊做群體智能預測。覺得這件事實在太有趣了,想說台灣選舉這麼精彩,何不自己做一個來玩看看?
於是我花了一段時間開發了一套叫 Civatas的社會模擬系統,想試試能不能用 AI 來模擬真實選民的思考過程,而不只是做傳統的數字民調。
這篇文章是一個技術實驗的紀錄這是粗體字,會盡量白話地說明方法和結果。
---
先講結論
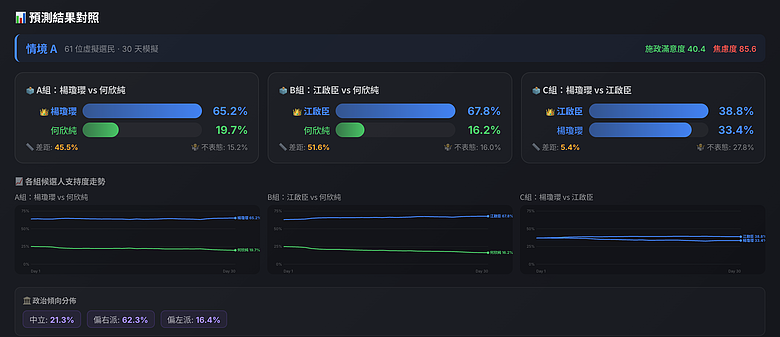
模擬題目:「國民黨台中市長黨內初選,楊瓊瓔 vs 江啟臣?」
我設計了三組交叉比較 (完全比照初選規定的全市話 對比 85% + 互比 15%):
| 組別 | 候選人 A | 候選人 B | A 得票 | B 得票 | 不表態 |
|------|---------|---------|--------|--------|--------|
| A 組 | 楊瓊瓔 | 何欣純 | **65.2%** | 19.7% | 15.2% |
| B 組 | 江啟臣 | 何欣純 | **67.8%** | 16.2% | 16.0% |
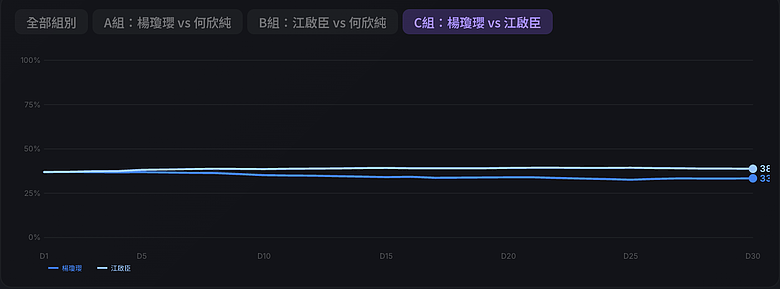
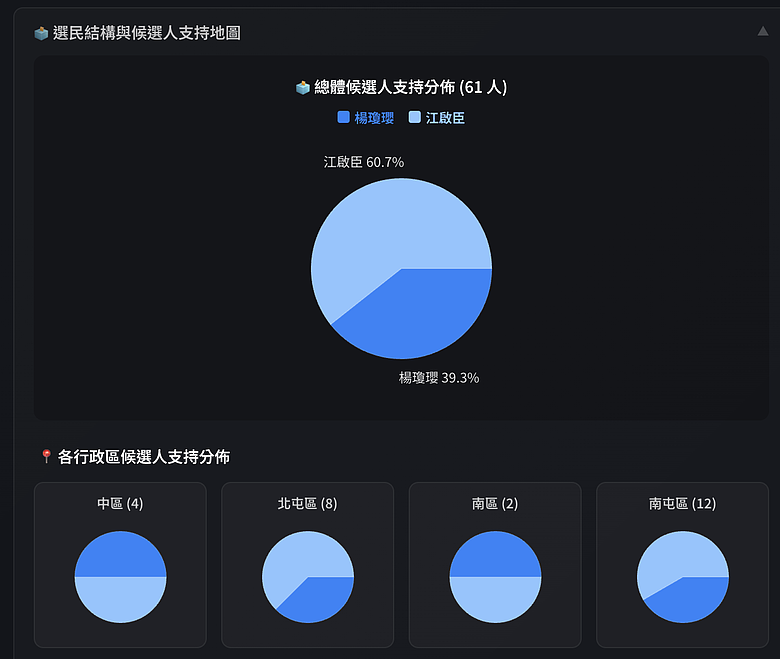
| C 組 | 楊瓊瓔 | 江啟臣 | 33.4% | **38.8%** | 27.8% |
白話解讀:
- 江啟臣 vs 楊瓊瓔:江啟臣以 38.8% 對 33.4% 領先約 5.4 個百分點,但不表態高達 27.8%,代表黨內支持者對兩人的區隔度感受不夠強烈,很多人還在觀望。
- 對上何欣純:不管派誰出來,藍營在台中都有明顯優勢。但江啟臣對何欣純的差距(51.6%)比楊瓊瓔對何欣純的差距(45.5%)更大,顯示江在吸引中間選民的能力上稍勝。
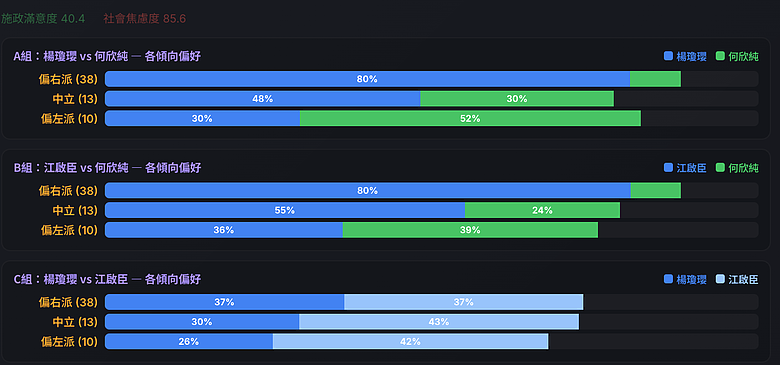
- 江啟臣的優勢來源:中立選民偏好江啟臣 42.8% vs 楊瓊瓔 29.7%;甚至偏左派(偏綠)選民中,江的接受度(42.1%)也遠高於楊(25.7%)。他的「學者形象 + 改革路線」對跨光譜選民有吸引力。
- 楊瓊瓔的優勢:在偏右派(深藍)選民中,兩人幾乎打平(36.6% vs 36.6%),楊的地方樁腳和盧秀燕團隊背景在基本盤是有效的。
---
這套 AI 預測到底怎麼運作的?
第一步:合成虛擬人口
我根據台中市的真實人口統計資料(年齡、性別、行政區、教育程度分布),合成了 61 個「虛擬市民」。每個人都有完整的背景設定:
- 基本人口統計(25 歲男性、住北屯、大學畢業......)
- 職業與收入水準
- 媒體使用習慣(重度社群 / 傳統電視 / 混合型)
- 政治傾向(偏藍 / 偏綠 / 中立)
- 性格特質(Big Five 人格模型:開放性、盡責性、外向性、親和性、神經質)
初始政治傾向分布是 34 偏藍、26 偏綠、1 中立,大致反映台中市的藍綠基本盤。
> 為什麼只有 61 人? 因為每個 agent 每天要呼叫大型語言模型(LLM)API 來「思考」,30 天模擬下來,61 人就要呼叫將近 4,000 次 API。如果用 600 人跑,就是 4 萬次呼叫,光 token 費用就很可觀。作為個人實驗,先用少量 agent 驗證方法論,未來確認合理後再擴大規模。
第二步:用真實歷史選舉做「校準」
直接拿模型跑預測太不負責了。我的做法是先拿過去的選舉來驗證這套系統到底準不準。
校準用的歷史數據:
我使用了台中市最近兩屆市長選舉的真實開票結果作為 ground truth:
- 2022 年(盧秀燕 vs 蔡其昌):盧 59.35% / 蔡 38.93% / 陳美妃 1.72%
- 2018 年(盧秀燕 vs 林佳龍):盧 56.57% / 林 42.35% / 宋原通 1.09%
而且不只是全市總票數,我還拿了台中市 29 個行政區的各區得票率做細部校準。例如:
- 和平區:盧在 2022 拿到 76.55%,2018 拿到 70.15%(深藍山城區)
- 清水區:蔡其昌在 2022 拿到 49.06%,幾乎五五開(蔡的票倉海線)
- 北屯區:盧在兩屆都超過 60%(重點人口大區)
校準的運作方式:
1. 把歷史選舉期間的新聞事件注入系統
2. 讓 61 個 agent 跑一輪模擬
3. 比較模擬結果與實際開票的 MAE(平均絕對誤差)
4. 系統自動調整幾十個參數(黨派基礎分、焦慮敏感度、新聞影響力、地方/中央施政權重......)
5. 重複調整直到模擬結果與歷史數據的誤差降到可接受範圍
6. 把這組參數「鎖定」,拿來跑未來的預測
這有點像機器學習的 train/test 流程,只是我的「模型」不是純數學公式,而是一群有人格、會看新聞、會寫日記的 AI agent。
第三步:注入真實新聞,跑 30 天模擬
校準完成後,我用同一組參數,開始跑「2026 台中市長國民黨初選」的預測模擬。
新聞來源:*系統自動爬取了近期 78 篇真實新聞**,涵蓋:
- 楊瓊瓔宣布參選、江啟臣表態、盧秀燕接班議題
- 民進黨提名何欣純、何欣純問政紀錄
- 盧秀燕施政成果(捷運藍線、社會住宅、觀光數據)
- 全國議題(物價、電價、兩岸局勢、國會改革釋憲)
- 賴清德中央執政相關報導
這些新聞被依照日期分配到 30 天的模擬時間軸上,越晚的天數累積越多資訊。
每一天,每個 agent 會經歷這個流程:
1. 個人化資訊推送:系統根據每個人的政治傾向和興趣,從 78 篇中挑選 5-7 篇推送。偏藍的人比較容易看到施政成果新聞,偏綠的看到更多中央政策報導。這是在模擬現實中的「資訊繭房」效應。
2. AI 寫日記:每個 agent 由 LLM 扮演,讀完新聞後寫一篇當天的心得日記。例如:
> 「盧市長施政不錯,交通治安有成就。但中央賴清德不配合,綠營囂張。物價壓力大,希望薪水追上來......」(偏藍 56 歲北屯居民)
> 「看到薪資中位數才 3 萬 8,超過一半人月薪不到 4 萬,難怪年輕人抱怨低薪。水湳招商聽起來不錯但要等......」(中立 28 歲西屯青年)
3. 更新情緒指標:每次寫完日記,系統同步更新三個數值:
- 地方施政滿意度(0-100)
- 中央施政滿意度(0-100)
- 焦慮指數(0-100)
4. KOL 影響擴散:系統隨機指定 3 位 agent 為意見領袖,他們的發言會影響周圍人的情緒。
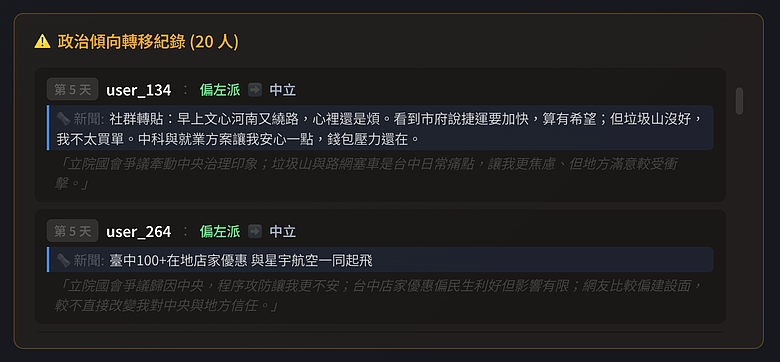
5. 政治傾向可能改變:如果一個人連續多天對施政極度不滿且高度焦慮,他的政治傾向可能從藍轉中立,或從綠轉中立。
第四步:投票估算
30 天跑完後,系統根據每個 agent 的最終狀態,用啟發式評分模型估算投票傾向:
- 黨派忠誠度:偏藍選民投藍營候選人有加成,反之亦然
- 候選人特質匹配:楊瓊瓔走地方路線(草根、基層服務),江啟臣走全國路線(改革形象、學者背景),系統會根據每個 agent 更看重地方議題還是全國議題,給予不同的偏好分數
- 焦慮效應:高焦慮選民更傾向支持「危機處理型」候選人
- 同黨初選特殊處理:當兩個候選人同屬一黨(如 C 組),自動關閉黨派加成,純比個人特質
---
30 天情緒演化的觀察
這是最有趣的部分。30 天下來,整體社會情緒發生了明顯變化:
| 指標 | Day 1 | Day 15 | Day 30 |
|------|-------|--------|--------|
| 整體滿意度 | 54.0 | 43.3 | 40.4 |
| 整體焦慮 | 70.9 | 80.3 | 85.6 |
| 偏藍選民焦慮 | 74.8 | 82.6 | 87.1 |
| 偏綠選民焦慮 | 65.7 | 67.5 | 74.8 |
觀察:
- 不管藍綠,焦慮都在上升。藍營選民焦慮更高,主要來自兩岸局勢和經濟不確定性。
- 滿意度全面下滑,但綠營選民下滑幅度更大(可能反映對中央施政的失望)。
- 偏綠選民有一部分在模擬中後期轉為中立(從 26 人降到 10 人),顯示在目前的資訊環境下,綠營認同度有鬆動的跡象。
政治傾向的流動:
| | Day 1 | Day 10 | Day 20 | Day 30 |
|---|---|---|---|---|
| 偏右派(藍) | 34 | 37 | 37 | 38 |
| 偏左派(綠) | 26 | 16 | 13 | 10 |
| 中立 | 1 | 8 | 11 | 13 |
綠轉中立的趨勢很明顯,但藍營基本盤相當穩固。
---
技術棧
最後講一下技術架構,給有興趣的工程師參考:
- 後端:Python FastAPI 微服務架構(人口合成、LLM 演化引擎、投票估算各自獨立)
- 前端:Next.js 14 + TypeScript
- LLM API:同時接了 OpenAI (GPT-4o-mini)、xAI (Grok)、DeepSeek 三家。每個 agent 隨機分配到不同 vendor,避免單一模型的政治偏見主導結果。某家 API 掛了會自動 fallback。
- 新聞系統:自動爬取真實新聞,個人化推送模擬資訊繭房
- 校準系統:用歷史開票數據做 MAE 最佳化,支援全市級和行政區級的精細校準
- 部署:Docker Compose,本機就能跑
---
這個實驗的侷限
老實說幾個已知問題:
1. 61 人母體太小:真正的民調至少 1000+ 人。但 LLM API 費用是硬傷,61 人 × 30 天已經消耗不少 token。
2. 新聞池影響結果:爬到的新聞如果偏向某方,結果就會偏。我在實驗過程中多次調整關鍵字平衡藍綠報導比例。
3. LLM 本身有政治偏見:不同模型對台灣政治的理解不同,這也是混用三家的原因。
4. 焦慮趨勢偏單向:模擬中焦慮只升不降,缺乏現實中「壞消息疲勞」的適應機制(我後來加了修正但仍不完美)。
5. 校準與預測的候選人不同:校準用的是盧秀燕 vs 林佳龍/蔡其昌,但預測是楊/江/何,人物特質轉移有不確定性。
---
所以你問我誰會贏?
以目前的模擬結果:
黨內初選 → 江啟臣微幅領先,但差距不到 6%,在不表態將近三成的情況下仍有變數。江的優勢來自跨光譜的吸引力,楊的優勢在於深藍基本盤的組織動員力,而這恰恰是模擬較難捕捉的。
跨黨對決 → 藍營優勢明顯,但何欣純在偏綠基本盤仍有五成以上的支持。差距沒有某些街訪民調顯示的那麼懸殊。
這只是一個技術實驗的初步結果。AI 模擬不會取代真正的民調,但它能提供一個不同的觀察視角——不只是「現在的數字」,而是「30 天內情緒如何演化、資訊環境如何影響選民思考」的動態過程。
如果有人對技術細節或方法論有問題,歡迎討論。
---



(本文僅為技術實驗分享,不代表任何政治立場,也不構成選舉預測。模擬結果僅供參考,請以實際選舉結果為準。)








































































































