

NVIDIA 這次在台北展示了 RTX GPU 在 AI 方面的應用,包括遊戲效能、顯示效果的提升以及個人電腦上的 AI 應用。
在三月份著重在大型資料中心與超算領域的 GTC 活動後,面對 Intel 跟 AMD 持續強調個人 AI PC 領域的創新,NVIDIA 雖然目前在這部分並沒有自家 CPU 處理器可說嘴,但是仍然透過自家 RTX 顯示卡在 Tensor Core 與 RT Core 的運算效能優勢,強調透過加入 RTX 顯示卡的運算加速後,才能在個人電腦上達到具備效率的 AI 運算效能。而這次也在台北 NVIDIA 分公司舉辦了小型的媒體說明會,透過現場展示的方式再度強調自家硬體在 AI 運算上的優勢。
首先來看 NVIDIA 官方在這次的簡報內容:

NVIDIA 再度在簡報中強調目前正是 AI 的『iPhone 時刻』,包括遊戲、內容創作、影片畫質、工作生產力、軟體開發以及日常生活應用等,更多層面都已經或是即將有 AI 加入,提供更好的體驗或是更高的運作效率。
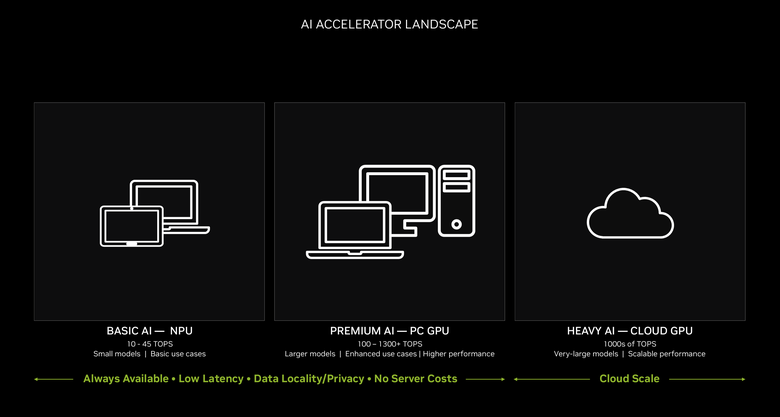
而目前的 AI 加速運算基本上可透過算力等級分為三大類,包括算力在 10-45 TOPS 的基礎 AI,這部分就是 Intel 跟 AMD 目前所推動的 AI PC 等級,主要提供小型模型的推論執行以及基本的使用者運用。
而中間的 100 至 1300 TOPS 等級,則是加入 GPU 加速的 Premium AI 進階 AI 運算,提供大型模型的推論、高效能/進階 AI 應用的執行。而更高階的重度 AI(Heavy AI)運用,就是在雲端伺服器或是超算機器上執行的 1000 TOPS 以上等級,提供超大模型以及巨量應用的執行。
其中個人可運用、不用連接到伺服器就可運作的,就是基本 AI 跟進階 AI 運算這兩部分,NVIDIA 也強調透過 GPU 的加速,不僅能讓個人電腦也能執行進階 AI 的運算,在基本 AI 應用上也更有效率。
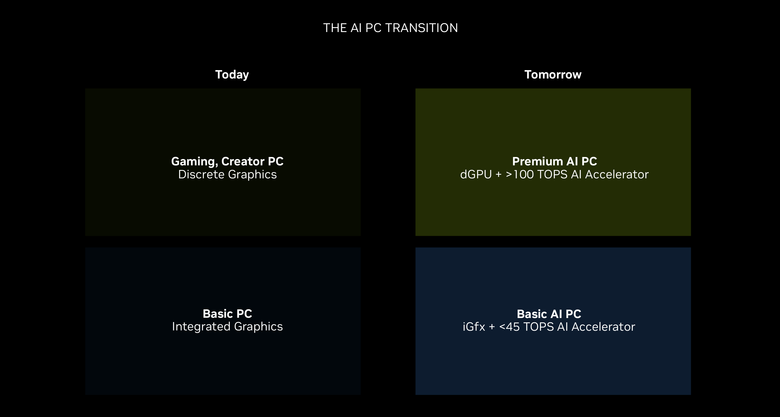
而在未來 PC 的規格也因為 AI 效能的需求加入,而有了新的改變,除了是否採用獨立顯示卡外,還要看 AI 加速器的效能來取決整個系統的效能等級。

NVIDIA 也公布了 Basic AI PC 跟 Premium AI PC 的效能分野,包括 AI 加速算力的不同,在內容創作、影像提升、生產力、遊戲與程式開發等部分,透過 GPU 的加速,讓兩者都有著不小的差異。(點擊可看大圖)
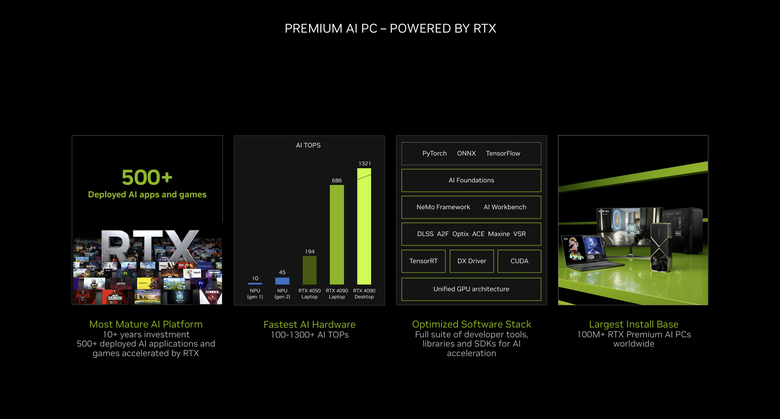
而 NVIDIA 也在 2018 年推出 RTX 顯示卡後,已經累積了相當豐富的生態系,包括 500 款以上應用以及遊戲、提升到 1300 TOPS 以上的 AI 算力、完整/最佳化的軟體開發架構,而目前已經有超過 100 萬部具備 RTX 顯示卡的 Premium AI PC 硬體被售出。
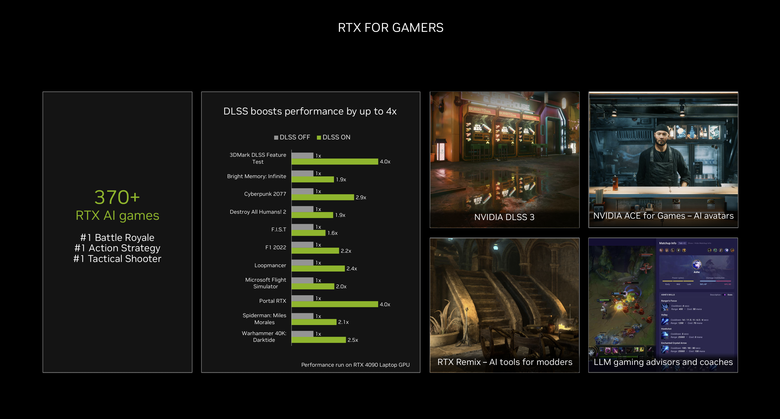
首先來看遊戲的部分,這也是 NVIDIA 最早運用 AI 在個人電腦的領域,大家所熟知的 DLSS 深度學習超高取樣技術就是其中代表,在開啟 DLSS 後,可以提升最高 4 倍的遊戲表現,但是對於畫質卻沒有太大的損失。而另外還包括了可讓老遊戲透過 Mod 重生的 RTX Remix 技術、幾乎可比擬真人對話的 NVIDIA ACE NPC 系統以及透過大型語言模型提供遊戲建議的教練系統等等,都是 NVIDIA 在遊戲部分強調已經或是即將問世的 AI 功能。

簡報中當然不免俗的展示了 DLSS 開啟前後的差異,畫面透過《電馭叛客 2077》(Cyberpunk 2077)遊戲來展示了最新 DLSS 3.5 在畫質以及幀率提升上的進步。
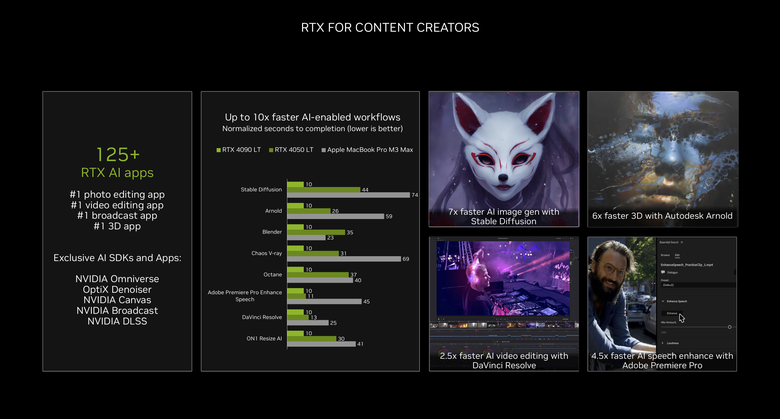
而在內容創作的應用部分,NVIDIA 也強調目前已經有 125 款以上支援 RTX 顯示卡的 AI 應用,包括照片、影片編輯、直播應用以及 3D 繪圖應用等等,另外 NVIDIA 也提供了獨家的 AI 開發工具與應用,包括 NVIDIA Omniverse、OptiX Denoiser、NVIDIA Canvas、NVIDIA Broadcast 等等。而在實際效能表現上,透過 RTX 顯示卡的加速,更是比單純 CPU 處理器的機種(這邊是用蘋果的 MacBook Pro M3 Max 來比),在各領域的 AI 運算要有 2.5 倍至 7 倍不等的效能領先。

而超過 125 款以上的 AI 應用軟體支援更是 NVIDIA 在這部分的優勢。
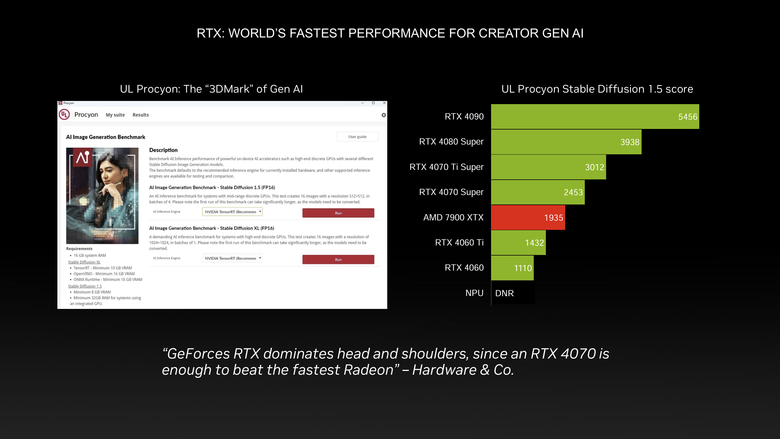
而在生成式 AI 部分,以目前最容易重現測試的 UL Procyon Stable Diffusion 測試中,NVIDIA 的 RTX 顯示卡更是效能上的領先者。
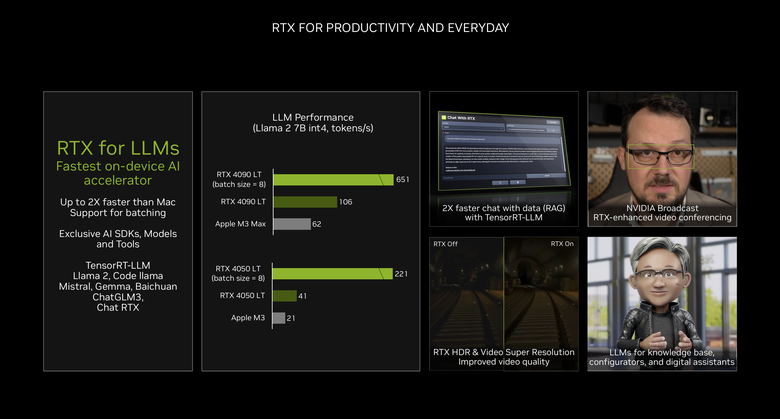 至於在大型語言模型的本機執行上,RTX 顯示卡也能提供比競爭對手快兩倍的執行效能,並且提供更豐富的支援性。
至於在大型語言模型的本機執行上,RTX 顯示卡也能提供比競爭對手快兩倍的執行效能,並且提供更豐富的支援性。
而目前 Basic AI PC 最常用來展示的視訊背景虛化功能,透過 RTX 顯示卡以及 NVIDIA Broadcast 軟體的配合,能夠提供更好的背景/主體分離判斷、可設定的虛化效果以及更可靠的眼神修正。
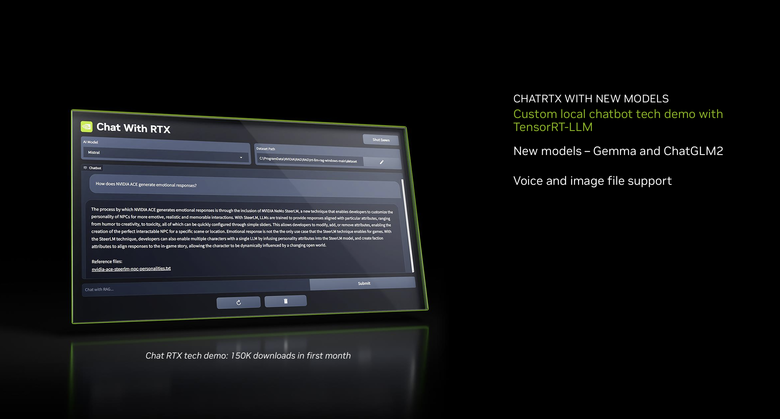
而接下來 NVIDIA 也將針對可在本機上執行 LLM 大型語言模型的 Chat RTX 功能(請見:專屬個人 AI 應用登場!NVIDIA Chat with RTX 開放下載試用),在下個月推出支援 Google Gemma 與 ChatGLM2 模型以及可辨識圖片的新版本,最大的進步就是可以支援中文啦!
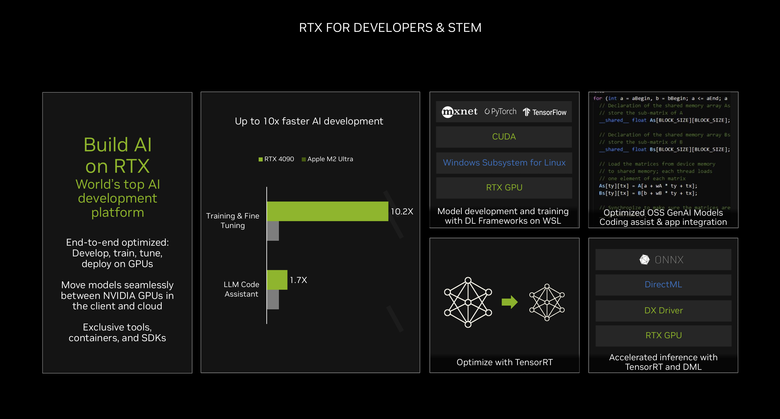
至於在開發者以及科學/工程教育( STEM)領域,NVIDIA 則是透過最佳化/開放的開發平台/開發工具提供更好的 AI 開發環境。
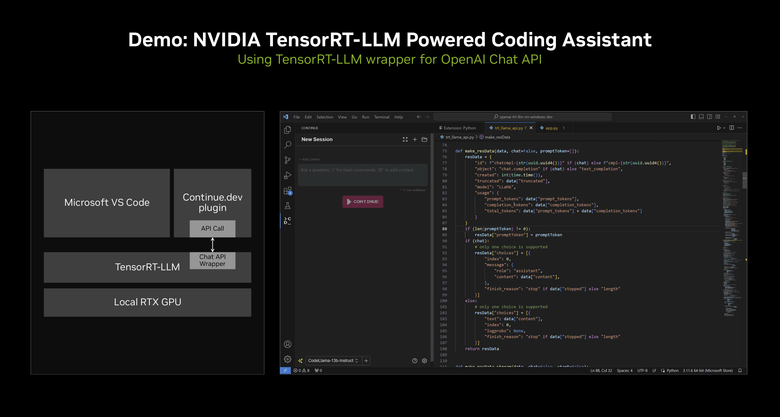
現場也直接 Demo 了一段利用聊天機器人進行程式碼最佳化的示範。
NVIDIA 實際展示
接著就來看實際展示啦,首先是在 CES 展示過的 DLSS 3.5 「光線重建(Ray Reconstruction)」功能(請見:【CES2024】NVIDIA 展示旗下遊戲相關 AI 應用 透過 AI 讓 NPC 遊戲角色提供真人般互動反應!),透過 NVIDIA 超級電腦訓練出的人工智慧網絡取代手動調整的降噪器,在採樣光線之間生成更高畫質的像素,為所有 GeForce RTX GPU 提高光線追蹤影像品質。
現場依舊使用《心靈殺手2》(Alan Wake 2)這款遊戲進行示範,不過這個展示跟陳拔在 CES 上看的是一樣的,主要在畫面幀率提升時仍然保有相當豐富的光影細節。
- 開啟 DLSS 前

- 開啟 DLSS 後

RTX HDR:NVIDIA App

NVIDIA ACE:Covert Protocol

另外一項相當受到玩家矚目的 NVIDIA ACE AI NPC 功能也在這次的展示之列,可以讓遊戲開發者運用 NVIDIA Audio2Face 支援的臉部動畫,搭配 NVIDIA Riva 自動語音辨識(ASR)和文字轉語音(TTS)技術支援的語音輸出,遊戲 NPC 角色提供更生動的互動。(請見:【CES2024】NVIDIA 展示旗下遊戲相關 AI 應用 透過 AI 讓 NPC 遊戲角色提供真人般互動反應!)
現場展示的《Covert Protocol》技術展示內容則是由 Inworld AI 與 NVIDIA 合作開發,Inworld 的 AI 引擎整合了 NVIDIA Riva 和 NVIDIA Audio2Face,前者能夠做到精確的語音轉文字,後者能夠做出逼真的臉部表情。
新版 Chat RTX
現場也展示了上面提到的新版 Chat RTX 個人AI 應用,讓使用者能夠將資料連接到有著 RTX 支援的 PC 上的大型語言模型,從自己的檔案和內容中快速獲取量身打造的資訊,以便在本地端安全地使用生成式 AI。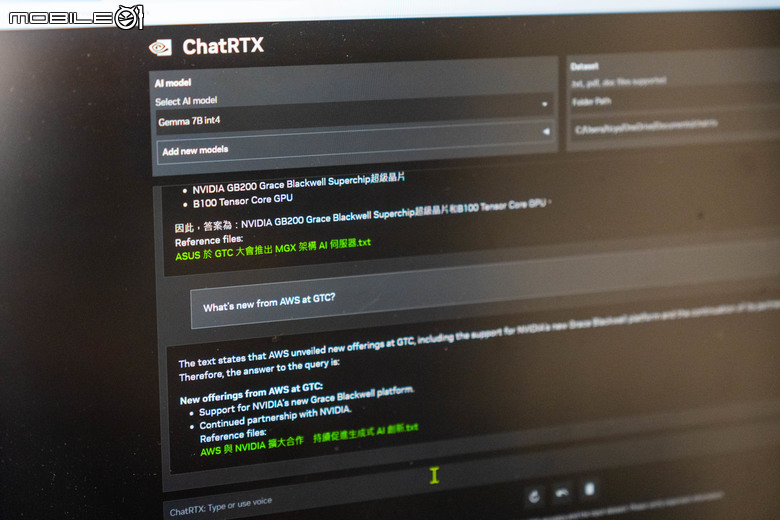
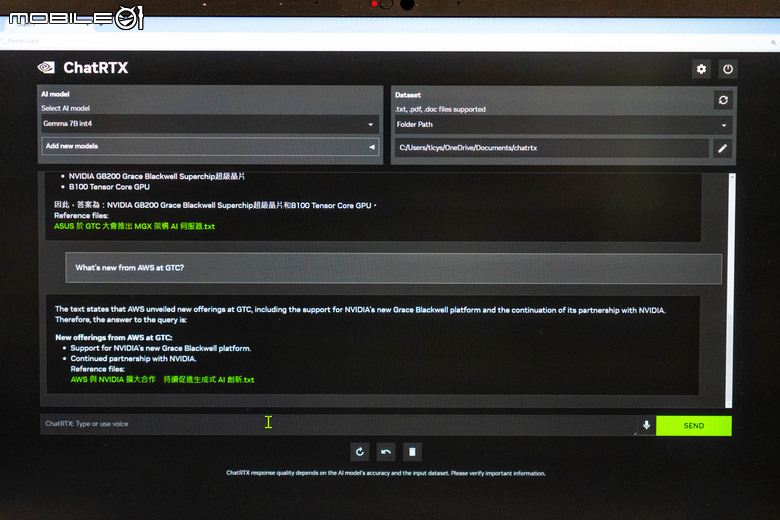
新版可支援 Google 的 Gemma 模型與 ChatGLM2 模型,提供中文的支援。
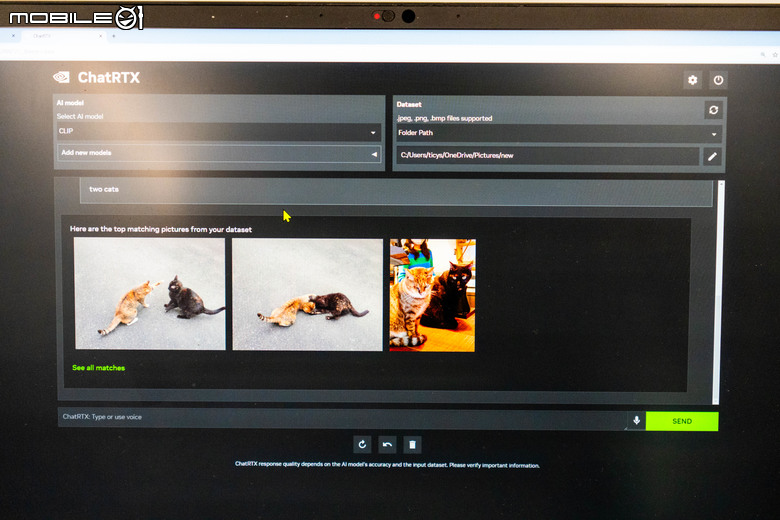
也可以透過 CLIP 功能輸入文字直接搜尋電腦裡的相關圖片。
Stable Diffusion XL 算圖加速功能

至於針對目前內容創作者比較常在個人電腦上執行的 Stable Diffusion AI 算圖應用,NVIDIA 也在今年CES 上,NVIDIA 推出了對 Stable Diffusion 擴充功能的更新,其中包括對 Stable Diffusion XL(SDXL) 的加速能力,SDXL 可產生比以往的 Stable Diffusion 模型更高品質的圖像,但其執行速度會慢 5-6 倍,使效能問題在許多系統上成為阻礙。然而,透過NVIDIA新推出的 RTX 加速,與之前最高的執行速度相比,TensorRT 將執行效能提高了 60%。現場也直接拿了一台具備 RTX 4090 顯示卡的筆電(右)來跟蘋果的 MacBook Pro M3 Max 處理器機種進行比較。
- 2 分 47 秒

- 9 秒

在同樣的設定條件下,採用 RTX 4090 顯示卡的筆電僅要 9 秒就能出圖,MacBook Pro M3 Max 則是需要接近 3 分鐘才能算完。



 英偉達目前AI無敵
英偉達目前AI無敵




































































































